Process Queues
Process queues are the mechanism that Instalink uses to defer processing to a later time. This is an important design pattern which makes it possible to create a stack of outbound requests that will be executed roughly in the order of earliest queued items first. The queued items make use of parallel processing and are executed as quickly as possible. The queued processes will also yield to inbound requests. This ensures that all in-progress data flows execute efficiently.
When to use a Process Queue
Instalink operates most efficiently when the data size remains consistent throughout the lifecycle of the data flow. For example, an endpoint that accepts a single record and sends that record to an external endpoint will run quickly and be simple to scale. In this case, the data stays consistent and the magnitude of operation is always 1 to 1. However, in practice, data flows are often not this simple. Often it may be necessary to perform multiple outbound calls for every inbound record. There may also be situations where a data flow accepts hundreds of records on a single inbound request and then must perform one or more outbound calls for each. It is important to utilize process queues for these outbound calls to allow the data flow to create a stack of requests that can be called when the processors have available resources.
It is recommended to use a process queue anytime it is expected that a data flow process will take longer than it is reasonable for the endpoint caller to wait for a response. For example, if an endpoint caller sends in 1000 records, and it is known that each record will take 1 second to process, it would be unreasonable to expect the caller to hold the connection open for 1000 seconds. It is better to accept the data, quickly submit it all to the process queues, and then respond to the caller that the data is processing. An outbound call can then be sent to an external endpoint to acknowledge when the process queues have been completed.
Use process queues to take advantage of the parallel processing features of Instalink. By default, Instalink allocates a single processor core to an account. However, it is possible to allocate additional processors to an account. The number of process queue items that can be executed simultaneously is directly proportional to the number of processors that an account is running. So, in an example where there are 1000 records and each record takes 1 second to process, an account with 1 processor will take 1000 seconds to complete. An account using queues with 5 processors will complete that process in 200 seconds as it is able to process 5 records simultaneously. However, an account with 5 processors that does not use process queues will still take 1000 seconds to complete as the data flow will only execute on one of the 5 processors. This is because inbound requests are load-balanced and assigned to one of the account's processors. The processor that initiates the data processing will handle all subsequent processing for the data flow unless process queues are used.
Process queues also make it possible to automate outbound call retries. This allows a data flow to gracefully handle temporary outages in external systems so that no requests are missed.
How a Process Queue Works
The queue action tells the data flow to defer all subsequent processing to a later time. When the queue action runs, it stores the exact state of the process data and then adds a record to the queue stack. The queue service receives a notification that the queue item is waiting to execute. All subsequent processing on the current instance of the data flow is immediately stopped and associated resources are released so that the processor can be used for other data flows.
The queue service quickly sends a notification back to Instalink which gets load balanced to all the available processors that the account has provisioned. Instalink immediately sends an acknowledgment back to the queue service that the notification had been accepted. The processor loads the process data as it was when the queue item was generated. The data flow then continues from that point until it completes its tasks. The queue item is marked as completed once all actions have been resolved on the data flow. The queue service will then send another notification for the next item until all queued items in the stack have been processed.
The queue service generally prioritizes the running of older queued items before newly queued items. So the stack will run from oldest to newest. Due to the nature of concurrency, the order in which queued items are processed is not exact. It should not be assumed in the data flow that an older item will always run before a newer one even though that is generally the case.
When a data flow encounters an error, such as an error response from an external API, the data flow can optionally send a notification to the queue service that indicates that the queued item should be retried as soon as possible.
How to Implement a Process Queue
While process queues can be instantiated at any THEN or ELSE step of a data flow, it is most useful to insert a queue action just before an action that makes an outbound request. Outbound requests include Send to URL, Database Read/Write, or SFTP actions. Add an action just before an outbound request to defer its processing to a later time and on another thread.
For example, the following data flow will wait until the outbound request has completed before responding to the endpoint caller. This could be problematic if the outbound call needs to wait a long time for a response from the external service.
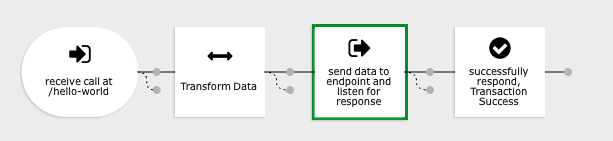
Address this issue by inserting a Queue Process action just before the outbound request. Add a FINALLY action which will respond to the caller when the queue is added to the stack instead of waiting until after the outbound call is processed.
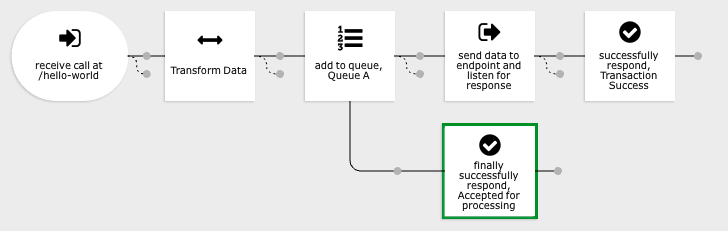
The Queue Process action has the following logical output operators:
- The Queue Process action will run subsequent THEN actions when the queue service sends a notification to the processors that it is time to execute the queue item.
- The Queue Process action will run subsequent ELSE actions only in the extremely rare event that there was an issue creating the queue item. An error action may be created on the ELSE branch to handle this unlikely situation.
- The Queue Process action will run subsequent FINALLY actions immediately once it has been confirmed that the queue item has been created on the queue stack.
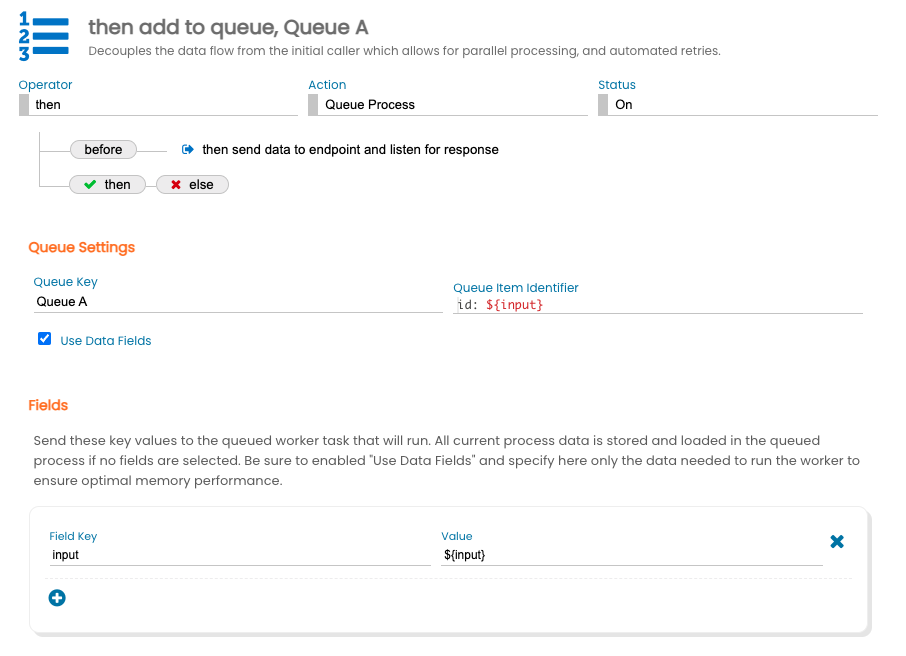
There are a few basic properties that must be set when using creating a Queued Process. The Queue Key identifies the queue stack that the queue item will be added to. Pick something that succinctly describes the purpose of the stack. DO NOT use a template to make the Queue Key unique. For example, setting the Queue Key to "${record.ID}" would result in many queue stacks being created.
The queue item identifier is used to identify the queue item in the stack. This value should be something that makes it easier to track the progress of the queue items such as a record identifier. The queue item identifier may also be used for deduplication purposes.
By default, all process data that exists in the data flow will be stored in the queued item and will then be reloaded when the queued item executes. It is important to only send the data to the process queue that the subsequent actions in the flow need to operate. Select "Use Data Fields" and manually identify specific process data that should be stored on the queue to ensure optimal memory performance. For example, consider an inbound request that has received 1000 records and the queue action is operating on only a single record at a time within a for each action. It would be extremely inefficient to store all 1000 records on each of the 1000 queued items. Instead, set the data field to only include the record that the queued item will process on each queue item.
Handling Error States
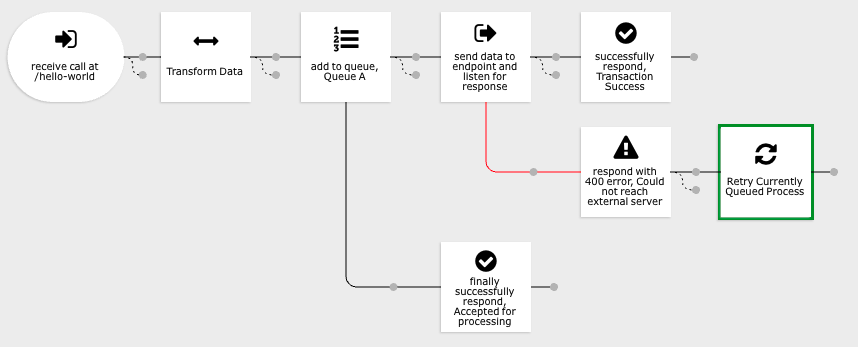
There are two action types that may be used to instruct the queue that the process is in an error state. "Retry Currently Queued Process" and "Fail Currently Queued Process". The Retry action tells the queue to wait a few moments and then reattempt the data flow at the next available opportunity. The Fail action tells the queue to immediately mark the currently queued item as "failed" and to not attempt to retry the process again.
The Retry action is useful in cases where an eternal service is temporarily down or is responding with status codes that indicates that it is unable to process incoming calls due to too much traffic. The Retry action should be used when there is a reasonable expectation that resending the call will result in a success.
The Fail action should be used when there is a reasonable expectation that no amount of retries will cause the remote service to return a success response. A situation where this could occur is when the external service is rejecting the data itself due to it being incorrect, missing required properties, or it is malformed. No amount of retries will cause the call to be successful as the data being sent needs to be changed. The queued item should be permanently failed in this case to prevent the service from needlessly sending calls to the external service that can't possibly be successful.
Viewing Queue Stacks
To view queue stacks in the admin panel, select "Process Queues" from the main menu. Search the queues for the desired queue and select one of the following links for that queue:
- View Queue Items: View a list of all queue items that exist for the queue. The queue items are stored for 60 days. Any specific completed or failed queue item may be individually retried. Any specific waiting queue item may be individually cancelled.
- Watch Queue Stream: View a live stream of queue items that are currently being added to and processed on the queue stack.
- Retry Queue: Select a time range and queue item status to select a batch of completed queue items to rerun.
- Cancel Queue: Select a time range and queue item status to select a batch of in progress queue items to cancel.
The Queue Item
Specific queue items can be found by searching by the queue identifier. Each queue item has one of the following statuses:
- Queued The item has been added to the queue stack and has not yet been picked up for processing.
- Running The item has been picked up by the worker and is currently processing data.
- Complete All tasks for the queued item have been processed without error.
- Scheduled for Retry The queued item process has logged a temporal error. The reason logged for the error is listed "Current Error". The next time that the queue will attempt to rerun the item is listed under "Retry (Estimated)".
- Permanent Failure The queued item process logged an error that should not be retried or the item has already been retried the maximum number of times.
- Cancelled The queued item has received a cancel notice from an administrator and will not be executed.
A queue item will automatically retry a maximum of 5 times. The time gap between retries is extended every time it gets rescheduled. The first retry will happen within a couple of minutes while the system will wait 45 minutes before attempting the 5th retry. In total, it would take over 2 hours for a queue item to exhaust its retry attempts.